And also
Concept
Principle
Short description.
Solution
- step
- by
- step
See also
- Related internal pages
- Related external pages
Inspiration
- Idea given by X with those contextual information
Back to the Menu
History of dominant cognitive models
Principle
List by time period the most popular abstract model of that time.
Solution
- ... before?
- atom and void, antiquity
- linear order in premodern Europe, ~XVIth century
- structure ...-1960
- system 1970-1980
- network 1990-2010
- code/software/turning machine (esp. for recursion)? ?-?
Remarks
- are there also dead-ends in cognitive models used? i.e. can a discovery not be made just by the model used and the inability to step back into another, an older one? (especially if considering a phylogeny of models in which one would require to backtrack through several branches)
- are they lagging behind the state of the art of mathematical constructs?
- e.g. what is the impact of category theory? topology?
- is that lag diminishing? (a form of compression, see earlier discussion on such a possibility)
- mainly through an intermediary democratizing physical layer i.e. computers?
- even more now through computers and their parametrized algorithms with their datasets directly available as services on the web?
- see also WithoutNotesMay11#JohnHopcroft conclusion on the central role of mathematicians
See also
Inspiration
Back to the Menu
Quantitative to qualitative threshold and the importance of automation
Principle
A threshold level can exist from which the seemingly useless accumulation of mode information or objects as quantitative aspect give rise to a qualitative shift. Automation because it allows the management of massive accumulation can facilitate a faster reach of such a shift.
Solution
- step
- by
- step
Remarks
- the desire to always automate can also be a dangerous bias of software developer who can neglect the cost of the process without first doing few cases, even one, is complex and might not be worth the efforts
- there can also be an upper limit in which once the threshold has been reach and new information is produced or behavior is modified, linear accumulation becomes insignificant, even too costly
- but also based on minimal potential structure: dated linked piece of information supporting addition and recursion
See also
- broadband government push in South-Korea
Inspiration
Back to the Menu
Optimal Learning Closure
Principle
Define the ideal state to learn.
Solution
- extract key features
- goal
- remember that the goal of the current task
- fixed by a parent closure
- feedback loop
- results of relevant measurements
- history
- track changes over time
- focus
- restrict attention on a specific object and a limited network of concepts
- know your needs Goal, focus, attention to remove them from the current task
- emulate those feature to build a dedicated environment
- note the results and improve
Examples
- learn Erlang directly in a code-repository
- goal: display the goal as the window title
- feedback loop: measure the distance between the distribution of the vocabulary used and the distribution from high quality Erlang programmers
- history: Mercurial tracks changes to code and comments
- focus: use
/startprogramming in irssi to remove notifications (social aspect) yet lot messages and switch to a dedicated screen window
- learn XXth century epistemology in a book
- learn reading in school
- learn a research domain in a laboratory
Remarks
- closure is preferred to environment in the sense that
- a closure can be created
- a closure can embed another closure
- relations are viewed in a hierarchical perspective, not as a network
- this could be an over-simplification yet provide a useful model
See also
Inspiration
- working on vocabulary building during computer language discovery (Learning New Language) and defining closure as a key terms in Innovativ.IT documentation (back from DataPublica)
Back to the Menu
Learning New Language
Principle
Every morning get a list of the new functions in your code repository to briefly review them to actively refresh your memory.
Solution
- define a pattern for keywords
- e.g W+( like "sort("
- parse the initial revision of the repository for all keywords
- filter out very basic functions
- periodically extract keywords since the previously parsed revision
- display the list of new keywords
- code snippet
- link to internal notes
- link to the official documentation
- with examples
See Repository:?p=.git;a=blob;f=shell_scripts/)logs_own_vocabulary and Repository:?p=.git;a=blob;f=shell_scripts/)most_used_commands.
and Repository:?p=.git;a=blob;f=shell_scripts/)most_used_commands.
Remarks
- basically any language based on the mastery of a large vocabulary
- if one just cram them up on a daily basis, he might recall 20% of those functions
- if he can review them and in a context in which he was involved
- he should remember not simply names but also how they relate to each other chronologically and contextually
- the The Language of Thought Hypothesis could also suggest that designing your own language (cf Languages#MakingYourOwn and Seedea:Reseach:PhylogeneticFlowProgramming
 ) could still be worth the investment
) could still be worth the investment
See also
Inspiration
- discovering Mercurial and accumulating more and more command names
Back to the Menu
Cognitive Mirror
Principle
Be able to leverage your own generated content for self study.
Solution
- generate data
- input those data in what you consider the most adapted AGI
- dialog with the result
Remarks
- software logs are activity mirror with a time dimension
- they do not reflect the current or then state of the object manipulated or the user yet they provide very interesting reflective information
See also
Inspiration
- Listening Introduction to Probabilistic Logic Networks from AGI Summer School 2009 while thinking about applying RelEx to my own wiki then looking at the mirror in the kitchen in Langrolay.
Back to the Menu
Cognitive Stack
Principle
Use the stack model common in computer science and networking to human cognition.
Solution
- describe a though
- cut in steps
- generalize
- test
- back to 1
- refine
- extend
- Cognitive Stack leveraging Programming#EntireStack for Exocognition As Network Traversal
- modelize as 1 single call trace
Remarks
- interestingly enough some of the "hard limits" of cognition seems to follow the same principle
- recursion limited by the number of deictic pointers that can be used
- task switching limited by the complexity of the context involved (a la paging)
See also
- MyBeliefs
- Cognition
- discussion seedeabitlbee/Paola 16/07/2010 from 20:03 to 20:38
- chain metaphor at 14m33s in Connectomics by Sebastian Seung, Living Systems DC Salon 2010
- discovered few days after writting this proposal
Inspiration
- discussion on why intuition is totally weak
- you can't backtrack your thinking process thus can't debug it thus can't learn
- discussion with Paola who were able during a conversation to backtrack to the previous topic and restart it
Back to the Menu
Analysis of the usage histories of tools
Principle
keep track on history of nearly every tool I use in order to be able to comment on new commands and avoid forgetting and parsing the docs again.
rote learning doesn't work that's why using history is important, it requires that you "do" the stuff, that you use it
it's not about reading the doc it's about using the tool (being a language or whatever) in a meaningful way for you
Solution
- list history files from Tools I use
- example of Irssi, Vi, Vimperator, Shell, ...
- result is outputed on a wiki with RSS feeds for recalls every few days (exp curve) MemoryRecipe
- perform analysis on keyword usage in a revert way and point to the doc page of the "popular" keyword that Im not using
- example if Im never using GROUP BY while everybody does, it would send me a link to
Remarks
the problem is that if it's not automated, it's too slow and clumsy, I can't do it manually else it will break my thinking process
like if I work on sth, I work on sth but once it's done, I dont want to have to lose the problems and solutions I had
Command-line clients are always a good solution when they can handle paremeters as the shell environment will record the history even when the tools do not.
See also
Inspired by
DrumbeatParis#VisitedLinks based on the browsing history in Firefox.
Back to the Menu
Dedicated Creativity Time
Principle
Creativity.
Solution
- meet plenty of different people who do not know each other
- be open-minded
- within and outside of your field
- study very hard
- keep notes
- gather paper, pens, computers and plenty of empty space
- cut information connections (yes, Internet and mobile included)
- cf Goal, focus, attention (applying Greasemonkey#VirtualBlinders in "introspection" mode) and Brain Hijackers
- do not buy or awaits for "that next tool [you] really need to progress", just make it with whatever you have around
- welcome impromptu events
- stay playful and keep on smiling
- keep more notes of the results but also of the process
- do sports or walks, don't stay enclosed in a tiny space for too long
- try new things not only on what you work on but on anything, even including daily chores
Overall remarks
- this is one way that does work for me, it is by no mean the universal and sole way. Rather, everybody should have his or her own tailored to the way he or she enjoys it.
- step away from the block to consider it better only thinking about it, not seing or touching it as maybe the sculptor most important work is done at the cafe or looking at the sea and only then materialize through his movements later on
See also
Back to the Menu
Brain Hijackers
Listing by estimated impact on survival
Depending on the situation one is in.
- physiological needs (cf Health)
- endogenous
- sleep, food, pain, ...
- exogenous (cf Chemistry)
- psychotrops, nootropics, ... (natural or synthetic)
- social (cf Person)
- entrance of out-group member
- entrance of in-group member
- events
- mass
- sport
- World cup, Olympic Games, ...
- speech
- known language
- unknown language
- advertisement
- entertainment
- noise (that one is unable to model, associate to a signal with a meaning)
- for each sense
Notes and remarks
- impact amplitude, it can be both positive and negative
- if somebody makes a huge threat, people will listen
- if somebody makes a propose a huge opportunity, people will listen
- it can also be expressed as the absolute difference with your estimated baseline on that topic
- social
- hierarchical superior
- potential mate
- generalized AbBlock Plus
- Diminished Reality by Wolfgang Broll at Department of Virtual Worlds / Digital Games, Ilmenau University of Technology
See also
Back to the Menu
Exocognition as network traversal
Actor possessing a low resolution model of the tool using it as an interface (cf Optimizable Model Per Page, Seedea:Seedea/Services , ...) to the tool (cf Person "distributed/social cognition API", ... ) itself.
Physically when the tool is used it is a continous wiring through the neural network to the usage. It's clearly visible when the tool is modelled as such like a CPU or the Internet (cf Seedea:Utopiahanalysis/UniNetVerseVisu). When the tool is not usually described as a network one can still imagine it as through it's structucal model, as the atomic level.
Before using a tool one thus have to have a model of the himself and of the tool. Simulate how it could interact with it then finally simulate how it could leverage it for its own usage. It is thus one single pathway across a much large space of interactions. Consequently one can imagine this usage as the combination of two networks forming this single pathways. The actor is thus a physical network possessing a low resolution of the second network.
Note that however efficiency the tools used can be, they are only useful in the process that leads to a Goal.
Remarks
- note this process could lead to dangerous bias
- the tool used is the best one for the task
- the actor can confuse
- the tool potential with his ability to use it
- the tool resistance with his own
See also
Inspired by
Back to the Menu
Thinking Is Technical
Thinking is idealized while, like computing, it is a very physical process. Not a simple one but still physical and thus that can be improve through processes technical too.
Example of the pen and paper, calculator, agenda, etc.
Even through social means (cf egyptian scribs, ...).
See also
To do
- add notes from my notebooks
Back to the Menu
Learning a New Domain
Solution
- see Path:/pub/conversations/learning_new_field_example_plants.txt
- make a warning regarding videos that reading the paper or book or trying the software prior to watching the talk drastically improve the understanding
- in particular for complex structures, e.g. equations, code, visualization, etc that are primitives of the area
- ideally constructing a hierarchy of such primitives
- also allows to decide of the rhythm and fix possible lacking pieces of knowledge
See also
Back to the Menu
Epistemic elitism and consequences on group dynamics
Hypothesis
There are glass ceiling from Grandes Ecoles and systems of self-described academic excellence but those are not resulting from groups dynamics favoritizing members of the same group, rather they are self-maintained dynamics in order to maintain a high quality of knowledge. Alma matters from top schools are not necessarily rejecting different groups from their circle but their own desire to acquire, and eventually create, knowledge naturally pushes them to always look for better quality. This form of epistemic arm races ripples down social strata of society rather than the other way around.
Remarks
- there might also be a self-censorship or a self desire not to participate in activities in which you know alumni for schools that socially perpetually been in your milieu considered "better" than you. One rarely wants to be intellectually challenge in public, especially in French culture in which asking questions and even more explanations is often considered degrading.
- see also Seedea:Content/Newconcepts#Agnotology
- we are addicted to cognitively stimulating environment
- as we develop cognitive skills, there is simply no going back to less rich environment and some of the most challenging involve a social aspect too
Inspired by
- Being a guest at an informal conference at ENS
Back to the Menu
Postponing and procrastinating
Postponing, a decision or an action, means that the uncertainty is too high and the default choice or current situation is ok
- it automatically implies that
- you expect the uncertainty to decrease over time
- key information currently lacking will naturally appear without having any action to undertake
- better alternative with lower uncertainty will become available
- the default choice or current situation will not have an impact too negative
Remarks
- this could be reinforced by cultural bias
- mythology of the pure free market with access to perfect information
- solution could be to step back and reconsider how that decision impacts your overarching goals
See also
Inspired by
Back to the Menu
Goal, focus, attention
the absence of goal increases flexibility yes but it also increases uncertainty (which is very stressful) and provide no focus point (hard to leverage)
In the quote "Give me a lever long enough and a fulcrum on which to place it, and I shall move the world" attributed to Archimedes, in our cognitive world with knowledge worker and such, focus is your more powerful lever.
Goal
Remarks
- Greasemonkey#VirtualBlinders with its multiple modes, "introspection" being the strictest, and I:Site/UbiquitousNet
 are two sides of the same coin
are two sides of the same coin
- probably proportional to the expected impact of CoS
- thus consider (evolutionary) bias that would wrongly shift the focus on a task that is not crucial
Metaphor
- available CPU cycles including those hijacked by worms
- available neuron cycles including those hijacked by non-personal goals
- wasted APM in
Key structures
- Wikipedia:Default network
 network of brain regions that are active when the individual is not focused on the outside world and the brain is at wakeful rest.
network of brain regions that are active when the individual is not focused on the outside world and the brain is at wakeful rest.
- Wikipedia:Dorsal attention network (DAN) involved in voluntary (top-down) orienting and shows activity increases after presentation of cues indicating where, when, or to what subjects should direct their attention.
- Wikipedia:Ventral attention network (VAN) involved mostly, if not entirely, in involuntary actions.
See also
References
Back to the Menu
Reading Techniques
Import and structure
Remarks
- Diminishing returns is probably why you do not want to finish that book sitting on your shelf for the last 2 months
- chances are that you already learn the basic concept even before reading the book, your decision to buy and start to read the book was a mere confirmation of your interest
- reading the first chapter refined your model
- the more you read the less you learn since you have already understood the basis
- reading in 1 sitting is impossible for truly new concepts
- you need time to restructure your beliefs, if the concept you are currently learning through this book is reshaping them and their organization in a radical manner, you probably need time to spread this update
- similar with fractal image compression technique
- MPEG/JPEG/...
- increasing precision
See also
Back to the Menu
Opportunity Tensions
Principle
You detect potential opportunity matching your your predictions and trends yet, are unable to find a way to leverage them
Examples
- scalable on-demand IT infrascture (AWS)
- databases (datapkg) + ML (uclassify, Analytics1305)
Back to the Menu
YearlyOverview
Principle
What was the best book, why?
How were the different books related (trying to step back a bit) ?
What were the difficulties and lessons learnt (motivate me to push further rather than just reading "interesting" books) ?
Examples
See also
Back to the Menu
Optimizable model per page
Principle
hopefully getting an entirely formalized wiki with the ability to optimize each page
Process
- find for each page of the wiki a formal model of what it represents
- equation or an algorithm that will allow to simulate the principle in the page
- able to run simulations relative to the content of the page
- lot of models/simulations in academia about everything
- an optimization algorithm
- if none specific is found, generic one like those used in operational research
- running optimization per page would be done according to
Data would be on that page or in another page of the wiki, the thing is that hopefuly it should always have the potential to improve.
Examples
page about my plants
- algorithm = general plant metabolism model
- optimization = Liebig's law
- data = plants and resources (water+soil) quantitative description
Remarks
- I already wanted to force myself to have a model/schema/formalization for each page but I didn't really got to it so far but if I can find optimization fo each, it could be a strong motivation.
- making it an AmazonTurk task but then I would need to first do it for few pages and make clear example for turkers
- proposed Pre-reading model and Post-reading model in Template but nearly never applied it
- months after added "consider a set of rules" too, same problem
- consider iPython
Back to the Menu
Priority by economical system
Moved to Cognition.PriorityByEconomicalSystem
Principle
Associate a costs to actions, thus giving the basis for an economical system, in order to provide the necessary support for incentive on usage and optimization from improvements. High leverage actions should naturally be preferred over low impact hight requirements actions. Also, the system would favor an increasingly precise estimation of costs (which is probably why this can not be delegated even to AWS#MechanicalTurk).
Back to the Menu
Leveraging existing brain structures for new purposes
Brain areas that evolved to very specialized cognition function over eons should now be re-used in a new context efficiently.
Description
For the last few years I was focusing on learning new important concept and thus discarded authors are discoverers and vectors of those ideas. Since recently I started remembering the author names as I find it more efficient to do so. I also try to have a quick bibliography but, at least as importantly, to have a video recording in order to memorize the author voice (especially when later on reading his own work) and face (probably for visualization). I consider that I can thus relate to him (and his concepts) better than without doing this "side work" seemingly unrelated to the concepts themselves.
Generalization
Are there other similar situations in which face recognition, voice recognition, social network exploration, ... could be leveraged?
Critics
- Is it actually testable?
- Is it post-rationalization?
See also
- WikiBrain Mapping in order to get a better understanding of the actual cognitive structures
Inspired by
Discussion with Paola in Paris Vrin bookshop and the usefulness of bibliographies.
Back to the Menu
Pain from imperfect tools
Why does when your computer or network is slow it feels "nearly painful"?
- because you integrate tools like a part of yourself (cf Tool-use induces morphological updating of the body schema Current Biology, Volume 19, Issue 12, R478-R479, 23 June 2009 )
- because you physical pain and psychological pain are very close (cf Comment soigner la souffrance psychique ? Le T�l�phone Sonne, France Inter, October 2009 )
So with 1 and 2 you get the equivalent of physical pain when your cherished tools are not working well
It also applies the other way around, this psychological pain can be somaticize like stomach ache or headache.
Evolution sticks to the principle of minizing resources spent and organisms end up with overlapping structures for similar usages so... it sounds coherent.
It could also explain how some people end up rejecting tools that don't responder properly at a gut level and hit the screen or don't want to use a computer. Just one bad initial experience could have been physically painful for them and if not that tool, a related older tool like a calculator.
Note that social and physical pain seems be using similar structure in the brain.
See also
Back to the Menu
WikiBrain Mapping
Map this actively used wiki instance over a visual brain imaging model.
Objectives
- better understanding of the "state of the art" brain mechanisms (chronological lastly integrated brain areas, cf Wikipedia:Developmental cognitive neuroscience) not through memorization but through usage (or simulated exploration)
- efficiently centralizing page to follow the cognitive scalability principle and replace the automatically generated Site.AllRecentChanges and the created Fabien.LayeredModel (technical difficulty making it hardly usable)
- motivate an efficient and more systematic delegation of such mechanisms (as software)
- connect Daily Exercises Feed and Optimizable Model Per Page whenever possible to improve the physical habits associated to the purely thereotical models associated to it or sub-part of the process
- directly connect healthy physical behavior and improved cognitive results
- reticular activating system (RAS) and posture (cf Health with PostureMinder)
- nutrition in particular water, caffeine, fatty acids (cf Health#Nutrition)
- leverage Concept Tree fMRI project to display content probabilisticaly relevant to the task at hand
- display content associated with detected activated brain area
Process
- create a dedicated page
- WikiBrainMapping
- list the existing brain areas
- http://github.com/kanzure/brain/blob/master/human_brain.yaml
- binded to a visualization
- list the existing wiki pages
- create an associative table
- association can be done through tag (PmWiki Categories)
- use general "memory" as the default area
- it is crucial to list all pages (as opposed to the LayeredModel)
- the refine as much as possible
- provide an incentive
- Roadmap (in the "neo-cortex"?)
- integrate of external resources
- previously organized through Seedea
- Services
- DATAmatrix
- AImatrix
- Onlineoutsourcing
- should be already integrated thanks to Person.Person
- it can also be associated to areas related to tool usage
- see Content.KeyExperiments#MappingToolsToBody
- visualize activity
- edition (PmWiki and httpd logs) browsing (httpd logs)
- see DTI visualization tools
- Website Traffic Map Designweenie
- integrate non-content part of the wiki
- modules
- configuration files
- get reviewed by a neuroscience researcher
- simple blind validation
- use brain imaging techniques
- to display (lens HUD or classical screen display) pages associated to the currently activated brain area(s)
- discussion with Paola (2 Dec 09)
- assimilate visit paths (through trails or httpd logs) to Wikipedia:Neural pathways
- example of Wikipedia:Arcuate fasciculus as described during WatchingNotes#AGISummerSchool2009 lecture 12 by Allan Combs
Side note
This is entirely different from brain imaging on mind mapping :
- Brain Imaging is the process of producing accurate picture of a physical brain, here those data are used in order to map over, not as a way to simulate.
- Mind mapping is the process of taking notes in a structured fashion while being creative.
- previous solutions
- chronology
- nothing
- entry page (add it's history)
- AllRecentChanges page
- LayeredModel
- WikiBrain Mapping
- next?
- review each step
Consider also non great apes brain model structures, in particular birds in particular crow and ravens, cephalopodes, dolphins and elephants.
- distinguish patterns
- eventually propose an hybrid model
Study not the content but solely the organization of information and of processing components used in ObjectsExoBrain#HardwareConfiguration then compare to existing brain structures not through their expected usage but again, through their structural organization.
Remarks
- the beauty of information stored on flexible system, it can have multidimensional categorization
- I can tag an information by physical context of the event, physical position of the information itself, chrnological position, relative positive to other events, etc... they don't have to be mutually exclusive.
- Consequently, based on the task at hand I can use any of those dimension of even combination of dimension to access that piece of information.
- even if I don't personally recall a piece of information by its physical position in my brain, I still think in the long run, with brain imaging progresses and because it's non-exclusive tagging, it will be useful.
Cf discussion with Klevre "Well I'd like something that organizes it the same way my brain does." and nicktick the 12/07/2010 at 09:39 on freenode/##pim
- could corticogenesis by usage at the human and phylogeny provide a model to simplify learning brain areas and their position?
See also
- my notes on The Wisdom Paradox by Elkhonon Golberg
- Organization for Human Brain Mapping (OHBM)
- neuroscience equivalent of KML for geography,
- a "NeuroML" using voxel coordinates?
- datasets and visualization
- the connectome initiative and the resulting connectomics field
- MindModeling@Home (Beta) research project that uses volunteer computing for the advancement of cognitive science.
- ACT-R cognitive architecture (as Lisp functions modeled from fMRI data) from CMU
- Whole Brain Catalog developed by a team of researchers from the UC San Diego
- Wikipedia:Cognitive_architecture
- Brain-Inspired Information Technology edited by Akitoshi Hanazawa, Tsutom Miki, Keiichi Horio, Springer 2010
- ACT-R: ACT-R meets fMRI (2007) John R. Anderson, Yulin Qin, Dan Bothell
- in particular John Robert Anderson at CMU knowing he is "using fMRI brain imaging to track different components of the cognitive architecture in the performance of complex tasks"
- Volume of Interest (VOI) Drawing with BrainMaker by Terry Oakes
- BrainInfo using NeuroNames Ontology, University of Washington
- NeuroImage - A Journal of Brain Function
- vehicle for communicating important advances, using imaging and modelling techniques to study structure-function relationships in the brain.
- Building a Circuit-Diagram for the Brain by Jennifer Raymond, Stanford University 2009
- brainmap.org online database of published functional neuroimaging (fMRI and PET) experiments with coordinate-based (x,y,z) activation locations in Talairach space.
- Wikipedia:Memory-prediction framework by Jeff Hawkins, 2004
- Human Brain Mapping, Wiley
Back to the Menu
Cognitive Scalability
Why taking notes matter?
- Writing notes cost literally nothing (paper and computer space are both free)
- Time is the most precious asset
- free vs most precious thing = stop wasting your precious time and the time of your friends, write notes down.
(cf Content.PersonalInformationStream#Principle)
Consequently, one should use copping systems like Personnal Information Management (PIM) as presented in ourP.IM to replace classical paper notes which might still be limitating regarding processing capabilities (searching, ordering, ...).
Probably mainly composed of one's learning ability (integrate new models) and the ability to synthesize (how much you can compress your current models).
Yet, one must also be sure minimize the CognitiveDrag generated, i.e. have limit the system burden (like paperwork) or meta-task.
Example
Content.PersonalInformationStream pulls page numbers and similar information automatically from notes page, removing the need to duplicate information.
See also
Back to the Menu
my social network
Moved to Person
Principle
Many tools from research in social networking have emerged recently we must benefit from them, especially since our networks have grown a lot and if we want to be scalable and have quality relationships we won't be able to go further without coping tools (again).
Back to the Menu
Causal Reading Tree
Problem
How can I step-back and understand what lead me to my current knowledge?
A bibliography is a similar tool for the writer but for the reader, it's harder to backtrack what lead you to read a book or another.
Process
- generate it using
- obtaining
- chronological animation of the generated causal tree
- so that one can see it unfold moment by moment
- visually distinguish the topic, associate a color by category (tags)
- output to GraphViz code, embed as PmGraphViz
- link each book to its ReadingNotes page
Example
See progresses in Processing#ProcessingJS resulting in a visualization of network of book in ReadingNotes#Visualization.
- bookA (lead to read) bookB (lead to read) bookC and bookD
- bookA and bookC (lead to read) bookE
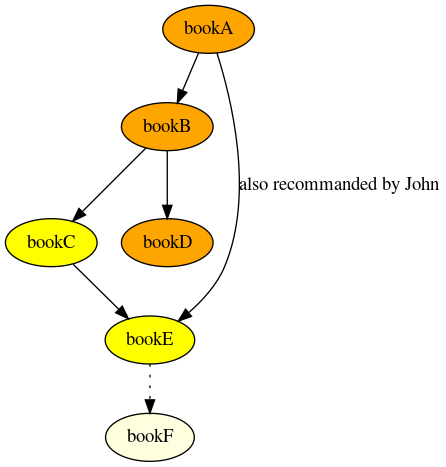
Example of animation
Back to the Menu
Private Library
Problem
PersonalInformationStream provides no link to my local files (or upload of them) as link to content implies giving an URL to the files thus uploading delay, copyrights issues, etc...
Process
- gives an URL to your collection
- edit /etc/httpd
- 127.0.0.1
- no upload and copyright problem
- remote server
- .htaccess required
- update InterMap of the wiki with the URL
- links page
[[MyLibrary:book_name.pdf#page=99]]
- http://partners.adobe.com/public/developer/en/acrobat/PDFOpenParameters.pdf
Example
[[MyLibrary:the Future of Ideas - Lawrence Lessig.pdf#page=10]]page10
search on "test"
To do
- Shared libraries
- 1 online server, each InterMap pointing to it
- distributed each InterMap pointing locally
- check simple mirroring mechanism, cvs-style
- print
- "Locate nearby Book Printer"
- use an international index of such printers and your location
- if nothing nearby, send to Lulu
- "Print Book" and send your PDF to it
Back to the Menu
Education Self-Update
- list the institutional books I have studied (from kindergarden to engineering school)
- find the notions that have since then been proven wrong
- highlight the new paradigms
- eventually generalize the result and make it a wiki to faciliate "getting up-to-date"
- mine the french Education National archive
- do this in collaboration with teacher friends, being teacher then or new teacher now
- Alain Burlot (physique-chimie)
- Mme Carre (allemand)
- Mme Buhard (francais)
- Claude Herviou (francais)
- Emilie Tanguy (general)
- Raphael Sonnier (general)
- Matthieu Herviou (mathematique)
- Frederic
- schools should provide such a tool in them and when one leaves them
- it would also impair the rote learning paradigm
- Institut National de Recherche P�dagogique (INRP)
- read a recent thesis a day each time from different domain
- locate RSS feeds for each key labs
- see also SCImago Research Group esearch group dedicated to information analysis, representation and retrieval by means of visualisation techniques.
- pick daily a lab (cycling through them)
- choose the latest most acclaimed onebased on popularity
Back to the Menu
Daily Exercises Feed
Currently partly implemented as ImprovingPIM#PIMBasedExercises.
- generate daily exercises feed
- based on the different wiki pages
- global repostory of exercises in a specific format by data type or domain
- periodically contributed by peer reviewed papers on education
- provide an API to pull the exercise form (as a template) and add content from other sources
- to finally provide
- generated exercises to be embedded (in a wiki, a feed reader, a link, ...)
- then every morning I would have an RSS feed with randomly picked exercises adapted to the content I want to learn (instead of always the same type, forcing me to be focused)
- feedback mechanism regarding exercises efficiency (eventually uniquely based on tests)
- a kind of WikiExercises to mashup content from Wikiversity/Wikibooks and other sources
- including based on previously read books
- Topicmarks upcoming feature "Answer quiz questions about the text"
Examples of wiki-based exercises
- is word X from page A, B, C or D?
- does page A contains word X, Y or Z?
- is page A linked to page B?
- what is the correct order for pages A, B and C on descending criteria i A>B>C? A>C>B? B>C>A? B>A>C? C>B>A? C>A>B?
- i e.g. size, frequency update, last edition, ...
- which of those page corresponds the updates visualization V, A, B or C?
Score would the be based on accuracy, number of answers and time required. It would be kept over time and tracking which questions one does fail the most at. Batches of questions would initially be of the same number but gradually updated to reflect the most frequently failed question.
See also
References
Back to the Menu
Thinking about thinking
Thinking is the process that extract information by transforming a probabilty distribution to another distribution using energy.
More classicly, your brain is an engine executing a process that updates its own neural configuration (a topology of weights) based on newly perceived information (external to itself) using energy acquired by digestion.
Discussions
Resulting questions
- What are the implication of such a framework
- for software?
- self-updating ANN (or other ML techniques)? cf log1 with Dira
- for learning?
- How can it be tested?
- Is the brain a large chemical manifold self-updating?
- can we expend to a "social manifold"?
- based on "joint attention is paradigmatically a distributed cognitive act. " (p153) Chapter 8 The Ontogeny and Phylogeny of Non-verbal Deixis of The Prehistory Of Language
- and the encompassing "Social Brain Hypothesis" also used in Institute of Cognitive and Evolutionary Anthropology, Oxford University
- can we expend this "social manifold" to tools too?
- including thus not just a network of biological neural networks (NN) but also Artificial ones (ANN) and thus forming an even more encompassing manifold?
- see discussion with Paola clarifying "networked statistical distribution", 18th of October 2009
See also
- Seedea:CoEvolution/HistoryIdeaManagement#CognitiveArcheology
- evolution from fixed systems (bones) to gears (Antikythera mechanism) then wiring (early computers) then FPGA then pure software on generic CPUs
- Artificial Intelligence in which most techniques are based on statistics
- the scientific method which rely heavily on coorelation to deduce potential causation, statistical tests, regression analysis, ...
- Information Geometry in which the concept of manifolds is central
- my page Cognitive Drag which goal is to minimize inefficiency in the thinking process
- Ray Solomonoff and his Universal Distribution
- The Streetwalker's Dilemma: A Job Shop Modelby Steven A. Lippman and Sheldon M. Ross, SIAM Journal on Applied Mathematics, Vol. 20, No. 3 (May, 1971), pp. 336-342
- HplusSummitHarvard#NoahGoodman on Probabilistic Lambda-calculus
- Information Geometry on Hierarchy of Probability Distributions by Shun-ichi Amari, 2001
- consider Wikipedia:Kullback�Leibler divergence (aka information divergence, information gain, relative entropy or KLIC and notated
||) discovered for definition of Φ in WithoutNotesMay11#IITManifesto
- Seedea:Content/Newconcepts#InformationGeometry
Back to the Menu
HUD for your PIM in the learning VR environment
See Overlay and Greasemonkey#RevertedPIMLinks
Get your imagination running
- take a picture from your daily life and add information over
- draw in very fine ink on plastic glasses
then design your HUD.
References
Automatic Feeds Good Practices
- boost discoveries of new items by monitor listings
- detect inactivity and suggest appropriate action
- as proposed in the To Do section of the New Concept page
- see also To Do section in new vocabulary, etc...
- inject serendipity, i.e. Wikiversity random
- eventually use this with SMW to make a daily random feed, configure the number of items, add the ability to inject the item in a SMW, etc
- potentially use an event-driven framework to produce/consume RSS (items as events) in coordination with time and other events
Back to the Menu
To do
- add workflows
- follow wiki.process.io models
- eventually build them there and link/embed
- import "E:\Work\Personnal tools\Reading process"
- link to my concepts tree in the cognitive scaffolding
- link to the article mentionning the Cognitive Commons
- link to Seedea/Services
- describe home sticky papers
- does PersonalInformationStream act as a feedback loop?
- (hopefuly) producing by public the positive effect on focusing on quality
- intellectual share and tell, Friday evenings
- talk about anything that you have learnt that week
- practiced by ThePhysicist
See also
- personal cognitive scaffolding
- the Education page
- Online outsourcing at Seedea
- resources on how to remotly delegate cognition
- looking for repositories of Cognitive Commons
- against mnemonics
- create a strongly connected network of logical links
- use the word/expression often in its context
- even if in the beginning it's "forced" like an exercise
- know the history of the concept
- where it comes from
- why it replaces the previous one, how it's different from existing ones
- know the ethymology
- the name itself has a logical construction
Inspiration
- doing it with food and objects, now with intangible objects.
Back to the Menu
 Fabien Benetou's PIM
Fabien Benetou's PIM










