Principle
have all my data integrated in an unifying "framework" (currently my wiki), not necessarily to spread out in different innovative cloud services, commercial or not.
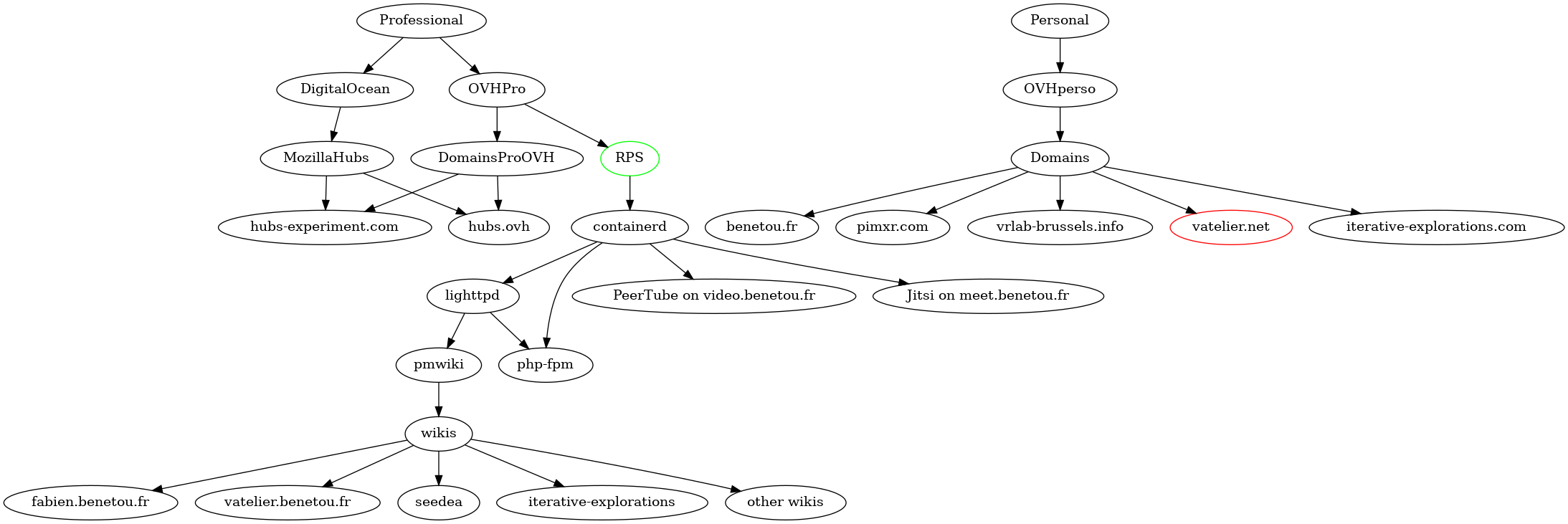
Color scheme : phasing out, gearing up.
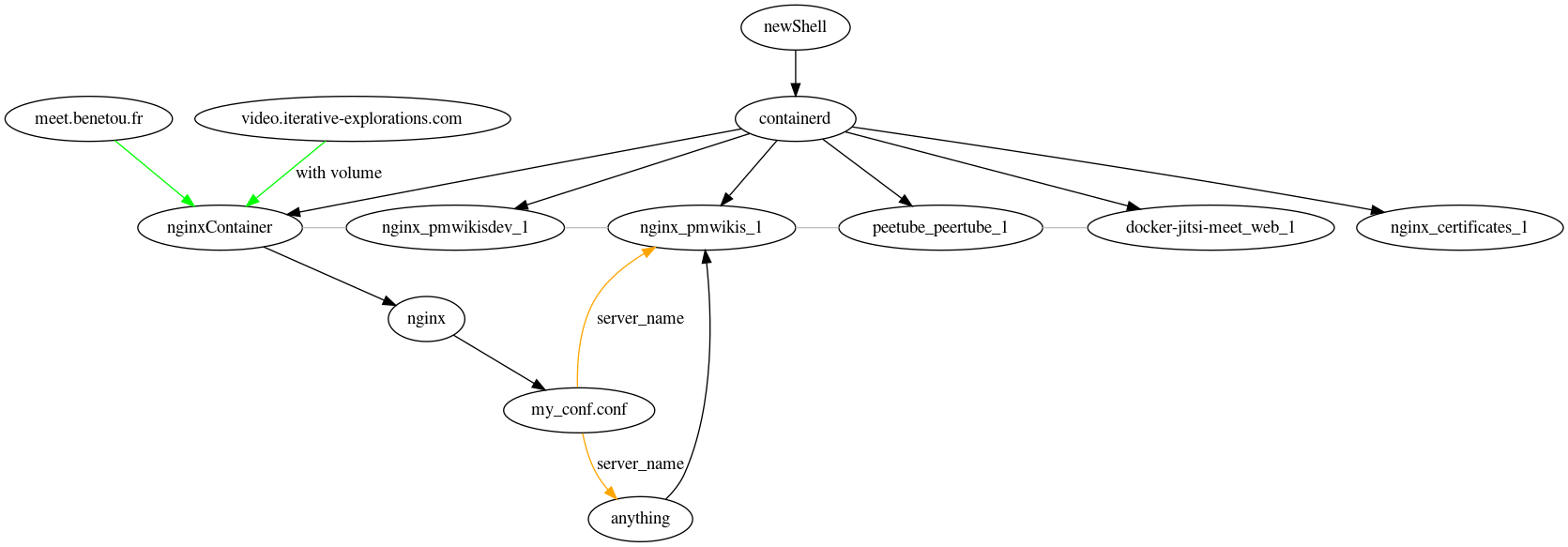
Color scheme : http, https.
See also Graphviz for an alternative view not based on infrastructure first by privacy.
cloud-init
- working cloud-init configuration
write_files to make files e.g .env
- generate it from a template then customize and load
- e.g
cp ci-template cloud-init; echo " - command" >> cloud-init
To try
Tried but didn't pursue
Tried but not fully functional
- remote backup
- NextCloud, have to adjust https for Collabora/CODE
Running
- gitea
- DockerProm with Graffana
Problems
- server mostly but not fully reboot proof and not format proof
- lighttpd OK, screen mostly OK (thanks to Screen stuff)
- laptop not format proof
- desktop not format proof
- backups not automated and Russian dolls format
- automatic rotating backups (cf rdiff-backup in Crontab)
- phone mostly mostly but not entirely format proof
To use
Solution
upload files
remove them locally
- set up tools I might need to feel "just like at /home".
- OpenVPN (currently using ssh for tunneling, pscp, sshs)
- treemap (demo set up)
- rsync (currently using pscp)
- scan the uploaded data folders
- propose to upload to websites per mime type, file extension
- if API are complex provide links to do so manually
- set privacy settings on by default
- example
- jpg, gif, png to Aviary.com
- ppt, pptx, pps, odt to Slideshare.net
- see Sphinxsearch for my own desktop search equivalent solution
- indexes can be shared
- locate former links to local fs
- search for
E:\Work\, file:///, etc
- e.g. Cloud:Documents/My%20Artwork/

- search for
discussion, irc log, etc
- e.g. Discussion:seedeabitlbee/paola.log#Date

- temp solution via Lighttpd on http://cloud.benetou.fr (consider Cookbook:StringReplace)
- search for
- allow fast searches
- once files are uncompressed build an index
- check updatedb / mlocate / find
- Cloud:index.txt
- update automatically with
- Crontab
- Wikipedia:inotify
 with its inotify-tools and incron
with its inotify-tools and incron
- provide a private http interface to it
- Cloud:find
- index meta-data
- index content
- for pictures and their galleries
- 1 line pic gallery (requires phat connection to the server, no re-sized thumbnails)
- echo "<html>" > gallery.html && ls *.jpg |sort -n| sed "s/\(.*\)/<a href=\"\1\"><img height=\"200px\" src=\"\1\"\/>\1<\/a><br\/>/" > gallery.html && echo "</html>" >> gallery.html
- example http://fabien.benetou.fr/pub/researchnotes/
- use
/etc/mime.types rather than harcdoded "jpg" extension
- efficiently use file and directory timestamps with Crontab vs gallery.html
- exifinfo, exifautotran, EXIFTool, exiftran, EXIFutils
- http://labs.ideeinc.com/ http://www.gazopa.com/ http://www.tineye.com/ http://www.numenta.com/vision/webservices.php
- consider OpenCV and dedicated GPU hardware
- export http://www.allmyapps.com/my/list/
- map configuration files to each application to the remote location of its backups
- manage emails
- set up mail server
- consider http://flurdy.com/docs/postfix/ and http://wiki.mutt.org/?MailConcept/Flow
- set up spam filter
- consider http://spamassassin.apache.org and http://postgrey.schweikert.ch
set up webmail
- http://mail.benetou.fr
set up DNS
- email friends with new adress
- redirect gmail non-spam to new address
- seems buggy
- download important emails from Gmail through pop/imap
- Backup up your GoogleMail locally with getmail by Ryan Cartwright, FreeSoftwareMagazine June 2010
- offlineimap Read/sync your IMAP mailboxes by jgoerzen
- OfflineIMAP with Mutt tutorial on ArchWiki
- automatize exchanges
- Crontab
- locally to
- download and unpack backups
- remotely to
- pack and make backups available
- check if OurPIM:Papers/PrivacySettings is respected
- ensure that the DNS if properly binded to most fundamental social services
- including VoIP
- test with Shell#EmbeddingShellClients
- consider content deliver per hostname
- especially initial configuration or configuration files
- e.g. this laptop would have this configuration, this one this other, etc...
Remarks
- down to ~5 files 5Go, trick is 0 media content I didn't produce so no DivX or mp3 collection, helps a lot.
- paradoxically at first was a kind of "discipline" but now is a pleasure since I use services like mixcloud and streaming websites with RSS
- do not just upload my mp3 collection then listen to it but prefer not to have a collection but to link to innovative services that do
- they are dedicated in that domain
- my typing input, even if I go as fast as I can, stays rather low so I should never need fast upload that way
- worse with asymmetric links, the case of ADSL
- I should move pointers to data around, not the data themselves, except for the one I produced myself
- Better Than Owning by Kevin Kelly, The Technium 2009
- "in the near future, I won't <<own>> any music, or books, or movies. Instead I will have immediate access to all music, all books, all movies using an always-on service"
- probably the only case in which large upstream bandwidth is required is video editing, pretty much everything else required large downstream bandwidth but low upstream
- HD crash resilient and "cloud buzzword compatible" policy ;)
- is it perfectly secure?
- no, no system either offline or online, remote or local, is anyway
- security by obscurantism does not work so posting information about this here is facilitating potential malicious person task but it is also strengthening my good practices
- consequently remotely stored backups and information loops are provided by default so that when (not if) problems happen, I can recover and fast
See also
Motivation for GNU/Linux transition on the client/interface side
- Licenses
 and communities
and communities
- infrastructure as code/package management
- kernel
- tiling wm
- scripting
- see also
To do
 Fabien Benetou's PIM
Fabien Benetou's PIM








