Based on PmWiki:PageListTemplates redirect and "search star" a la Google as suggested by Jonathan
- grep searchstar /var/log/lighttpd/access.log | awk '{print $7}'
- note that this is incomplete (because of logrotate) yet not necessarily a bad thing as older results could become less and less relevant
- log analysis can also be done with the Referrer field
- can it work without coming from the search page? does the referrer field include the full GET URL?
- LocalTemplates#searchresultswithredirectwithstarring allow starring
| Example | |
| With completion | (:searchboxcomplete :) |
| | (limited to Tools |
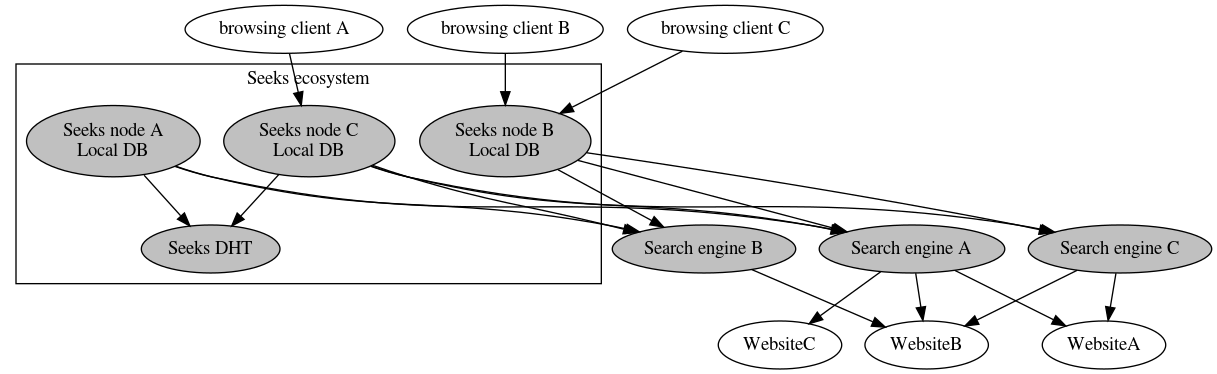
Visualization of Seeks principle
Problematic queries
- 12/08/11 "MIT logistic map that showed which part of an iPhone came from and where it was assembled, you could see the cradle-to-cradle footprint"
To do
add prototype.js completion solution for names of pages but also previous searches
- done before with Seedea search
 restricted to Seedea:OIMP/
restricted to Seedea:OIMP/
- 1 result redirection as done in local instance through Site/LocalTemplates#searchresultswithredirect
- compare with Google Instant which seems really close
- use Path:/pub/stared_searches.txt to redirect to stared search results, not just pages
- extend to content
- Keywords#inmybooks
- transcripts from videos and audios listed
- e.g. PersonalInformationStream.WithoutNotes
- patterns of transcripts location
- TED http://on.ted.com/23
- http://www.google.com/video/upload/video_transcripts.html
- http://www.archives.gov/social-media/transcripts.html
- http://help.youtube.com/support/youtube/bin/answer.py?hl=en&answer=166810
- YouTube's Interactive Transcripts June 2010
- Videocrux custom video player displays the TOC alongside the video.
- community based websites
- http://dotsub.com
- http://universalsubtitles.org (by Person:Felipe and others)
- http://www.opensubtitles.org
- http://www.allsubs.org
- include query reformulation
- check if it is legal to put PDFs on a public website but only allowed to crawlers e.g. GoogleBot so that it indexes everything one has read but without risking copyright infringement notifications
- now supporting indexing of pdf, doc, ppt, txt, etc... (documentation still to write)
- consider Cookbook:GlossaryPlus used with a filtered list from e.g. http://sphinxsearch.com/docs/current.html#ref-spelldump
- could first link to a search page for those
- uncommon expressions
- OwnConcepts?
- previous searches
- last searches
- most popular searches
- related searches (based on time, location, words, ...)
- search within archives
- filter off file too larges
- check available space
- uncompress all in temporary place
- index this temporary path
- keep archived specific path
- delete those uncompressed files
- search amongst indexed websites in PIM
- remove clutter via http://boilerpipe-web.appspot.com
- convert to HTML and ignore it (cf Sphinx option) or convert to text directly
- import and index with relevant attributes, e.g. source PIM page
- note that this must be incremental as very links are added on a daily basis but tons have been added until now
Overall see lab/improve_brain_search and lab/desktopsearch/to_index
See also
 Fabien Benetou's PIM
Fabien Benetou's PIM








